堆排序是一种原地的、时间复杂度为 O(nlogn) 的排序算法。
堆是一个完全二叉树;
堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
第一点,堆必须是一个完全二叉树。还记得我们之前讲的完全二叉树的定义吗?完全二叉树要求,除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列。
第二点,堆中的每个节点的值必须大于等于(或者小于等于)其子树中每个节点的值。实际上,我们还可以换一种说法,堆中每个节点的值都大于等于(或者小于等于)其左右子节点的值。这两种表述是等价的。
对于每个节点的值都大于等于子树中每个节点值的堆,我们叫做“大顶堆”。对于每个节点的值都小于等于子树中每个节点值的堆,我们叫做“小顶堆”。
往堆中插入一个元素
如果我们把新插入的元素放到堆的最后,有可能不符合堆的特性,我们就需要进行调整,让其重新满足堆的特性,这个过程我们起了一个名字,就叫做堆化(heapify)。堆化实际上有两种,从下往上和从上往下。这里我先讲从下往上的堆化方法。
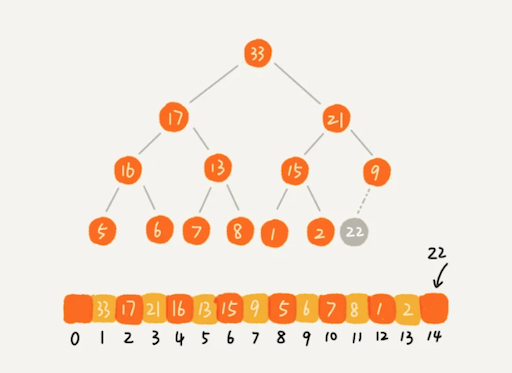
堆化非常简单,就是顺着节点所在的路径,向上或者向下,对比,然后交换。
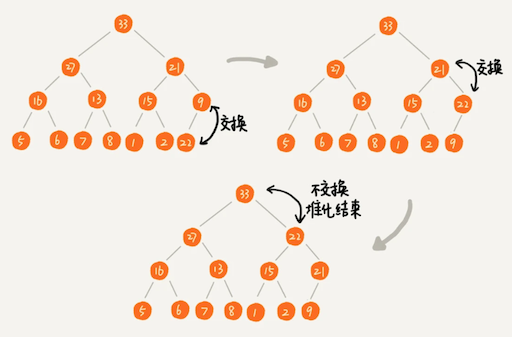
删除堆顶元素
种方法有点问题,就是最后堆化出来的堆并不满足完全二叉树的特性。
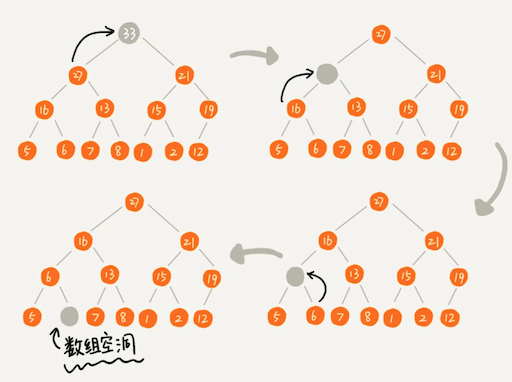
我们把最后一个节点放到堆顶,然后利用同样的父子节点对比方法。对于不满足父子节点大小关系的,互换两个节点,并且重复进行这个过程,直到父子节点之间满足大小关系为止。这就是从上往下的堆化方法。
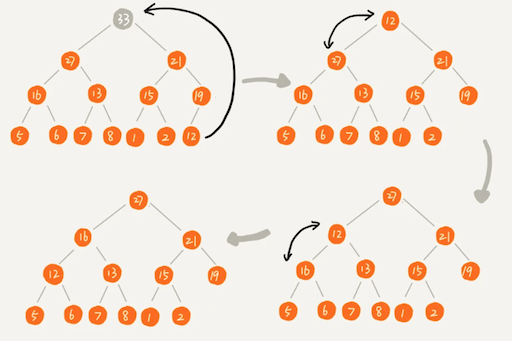
我们知道,一个包含 n 个节点的完全二叉树,树的高度不会超过 log2 n。堆化的过程是顺着节点所在路径比较交换的,所以堆化的时间复杂度跟树的高度成正比,也就是 O(logn)。插入数据和删除堆顶元素的主要逻辑就是堆化,所以,往堆中插入一个元素和删除堆顶元素的时间复杂度都是 O(logn)。
如何基于堆实现排序?
我们可以把堆排序的过程大致分解成两个大的步骤,建堆和排序。
建堆
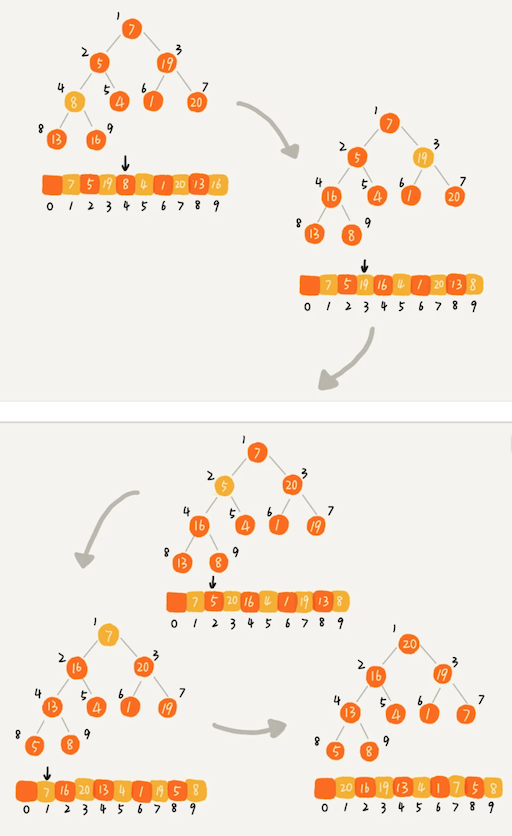
第一种是借助我们前面讲的,在堆中插入一个元素的思路。尽管数组中包含 n 个数据,但是我们可以假设,起初堆中只包含一个数据,就是下标为 1 的数据。然后,我们调用前面讲的插入操作,将下标从 2 到 n 的数据依次插入到堆中。这样我们就将包含 n 个数据的数组,组织成了堆。
第二种实现思路,跟第一种截然相反,也是我这里要详细讲的。第一种建堆思路的处理过程是从前往后处理数组数据,并且每个数据插入堆中时,都是从下往上堆化。而第二种实现思路,是从后往前处理数组,并且每个数据都是从上往下堆化。
1 | private static void buildHeap(int[] a, int n) { |
- //1 从最后一个非叶子节点开始,依次堆化
- //2 从上而下进行堆化
我们对下标从 n/2 开始到 1 的数据进行堆化,下标是 n/2 +1 到 n 的节点是叶子节点,我们不需要堆化。实际上,对于完全二叉树来说,下标从 n/2 +1 到 n 的节点都是叶子节点。
假设是个满二叉树

因为完全二叉树的高度=logn,s=n-logn,建堆的时间复杂度就是 O(n)。
排序
这个过程有点类似上面讲的“删除堆顶元素”的操作,当堆顶元素移除之后,我们把下标为 n 的元素放到堆顶,然后再通过堆化的方法,将剩下的 n−1 个元素重新构建成堆。堆化完成之后,我们再取堆顶的元素,放到下标是 n−1 的位置,一直重复这个过程,直到最后堆中只剩下标为 1 的一个元素,排序工作就完成了。
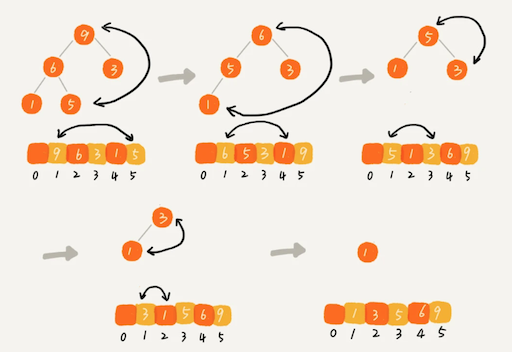
整个堆排序的过程,都只需要极个别临时存储空间,所以堆排序是原地排序算法。堆排序包括建堆和排序两个操作,建堆过程的时间复杂度是 O(n),排序过程的时间复杂度是 O(nlogn),所以,堆排序整体的时间复杂度是 O(nlogn)。
堆排序不是稳定的排序算法,因为在排序的过程,存在将堆的最后一个节点跟堆顶节点互换的操作,所以就有可能改变值相同数据的原始相对顺序。
为什么快速排序要比堆排序性能好?
第一点,堆排序数据访问的方式没有快速排序友好。
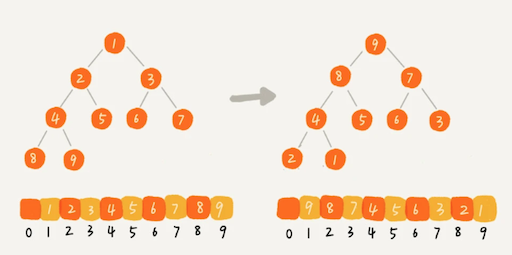
对于快速排序来说,数据是顺序访问的。而对于堆排序来说,数据是跳着访问的。 比如,堆排序中,最重要的一个操作就是数据的堆化。比如下面这个例子,对堆顶节点进行堆化,会依次访问数组下标是 1,2,4,8 的元素,而不是像快速排序那样,局部顺序访问,所以,这样对 CPU 缓存是不友好的。
由于CPU的计算能力远远高于我们现在使用的物理磁盘、内存,所以为了充分利用CPU,在CPU中存在一个类似内存的高速缓存(非常快,勉强满足CPU的计算能力),而CPU为了优化性能,会做一些“预测”动作。比如在读取数组中某一个下标为i的数据的时候,它会“自作聪明”将下标为i+1、i+2等数据也读取到缓存中以便下次计算直接读取缓存,不用等到磁盘再读取数据。所以顺序访问的数组比跳跃访问性能更好。
第二点,对于同样的数据,在排序过程中,堆排序算法的数据交换次数要多于快速排序。
我们在讲排序的时候,提过两个概念,有序度和逆序度。对于基于比较的排序算法来说,整个排序过程就是由两个基本的操作组成的,比较和交换(或移动)。快速排序数据交换的次数不会比逆序度多。但是堆排序的第一步是建堆,建堆的过程会打乱数据原有的相对先后顺序,导致原数据的有序度降低。比如,对于一组已经有序的数据来说,经过建堆之后,数据反而变得更无序了
堆的应用一:优先级队列
合并有序小文件
假设我们有 100 个小文件,每个文件的大小是 100MB,每个文件中存储的都是有序的字符串。我们希望将这些 100 个小文件合并成一个有序的大文件。
整体思路有点像归并排序中的合并函数。我们从这 100 个文件中,各取第一个字符串,放入数组中,然后比较大小,把最小的那个字符串放入大文件中,并从数组中删除。假设,这个最小的字符串来自于 13.txt 这个小文件,我们就再从这个小文件取下一个字符串,放到数组中,重新比较大小,并且选择最小的放入合并后的大文件,将它从数组中删除。依次类推,直到所有的文件中的数据都放入到大文件为止。
这里就可以用到优先级队列,也可以说是堆。我们将从小文件中取出来的字符串放入到小顶堆中,那堆顶的元素,也就是优先级队列队首的元素,就是最小的字符串。我们将这个字符串放入到大文件中,并将其从堆中删除。然后再从小文件中取出下一个字符串,放入到堆中。循环这个过程,就可以将 100 个小文件中的数据依次放入到大文件中。(取出堆顶元素后,直接再从小文件中再取一个放入堆顶接着堆化即可;单次时间复杂度=logn)
高性能定时器
假设我们有一个定时器,定时器中维护了很多定时任务,每个任务都设定了一个要触发执行的时间点。定时器每过一个很小的单位时间(比如 1 秒),就扫描一遍任务,看是否有任务到达设定的执行时间。如果到达了,就拿出来执行。
我们按照任务设定的执行时间,将这些任务存储在优先级队列中,队列首部(也就是小顶堆的堆顶)存储的是最先执行的任务。(任务的删除和插入,时间复杂度=logn)
堆的应用二:利用堆求 Top K
如何在一个包含 n 个数据的数组中,查找前 K 大数据呢?
针对静态数据:
可以维护一个大小为 K 的小顶堆,顺序遍历数组,从数组中取出数据与堆顶元素比较。如果比堆顶元素大,我们就把堆顶元素删除,并且将这个元素插入到堆中;如果比堆顶元素小,则不做处理,继续遍历数组。这样等数组中的数据都遍历完之后,堆中的数据就是前 K 大数据了。
比如数组 [4,5,3,7,1,8],要取前3大元素 首先维护一个小顶堆,放入前三个数据,为 [3,4,5]; 接着遍历数组到元素7,比堆顶元素3大,将3移除,将7放入堆中,小顶堆变为 [4,5,7]; 接着遍历数组到元素1,比堆顶元素4小,不处理,接着遍历; 接着遍历数组到元素8,比堆顶元素4大,将4移除,将8放入堆中,小顶堆变为 [5,7,8];
遍历数组需要 O(n) 的时间复杂度,一次堆化操作需要 O(logK) 的时间复杂度,所以最坏情况下,n 个元素都入堆一次,时间复杂度就是 O(nlogK)。
针对动态数据:
可以一直都维护一个 K 大小的小顶堆,当有数据被添加到集合中时,我们就拿它与堆顶的元素对比。如果比堆顶元素大,我们就把堆顶元素删除,并且将这个元素插入到堆中;如果比堆顶元素小,则不做处理。这样,无论任何时候需要查询当前的前 K 大数据,我们都可以立刻返回给他。
堆的应用三:利用堆求中位数
对于一组静态数据,中位数是固定的,我们可以先排序,第 2n 个数据就是中位数。每次询问中位数的时候,我们直接返回这个固定的值就好了。所以,尽管排序的代价比较大,但是边际成本会很小。但是,如果我们面对的是动态数据集合,中位数在不停地变动,如果再用先排序的方法,每次询问中位数的时候,都要先进行排序,那效率就不高了。
借助堆这种数据结构,我们不用排序,就可以非常高效地实现求中位数操作。
我们需要维护两个堆,一个大顶堆,一个小顶堆。大顶堆中存储前半部分数据,小顶堆中存储后半部分数据,且小顶堆中的数据都大于大顶堆中的数据。
也就是说,如果有 n 个数据,n 是偶数,我们从小到大排序,那前 n/2 个数据存储在大顶堆中,后 n/2 个数据存储在小顶堆中。这样,大顶堆中的堆顶元素就是我们要找的中位数。如果 n 是奇数,情况是类似的,大顶堆就存储 n/2 +1 个数据,小顶堆中就存储 n/2 个数据。
如果新加入的数据小于等于大顶堆的堆顶元素,我们就将这个新数据插入到大顶堆;否则,我们就将这个新数据插入到小顶堆。这个时候就有可能出现,两个堆中的数据个数不符合前面约定的情况:如果 n 是偶数,两个堆中的数据个数都是 2n ;如果 n 是奇数,大顶堆有 2n +1 个数据,小顶堆有 2n 个数据。这个时候,我们可以从一个堆中不停地将堆顶元素移动到另一个堆,通过这样的调整,来让两个堆中的数据满足上面的约定。
有一个访问量非常大的新闻网站,我们希望将点击量排名 Top 10 的新闻摘要,滚动显示在网站首页 banner 上,并且每隔 1 小时更新一次。如果你是负责开发这个功能的工程师,你会如何来实现呢?
在第一次将点击量Top10的新闻摘要显示到网页上时,我们先使用散列表,记录这一小时前到现在,每个不同的新闻摘要在过去的一个小时里,各点击了多少次。然后根据统计出来的散列表,构造出Top10的小顶堆,那么这数据规模为10的小顶堆就是这次需要放到网页上的Top10新闻摘要。
接着,在未来的一小时里,用哈希表统计未来一小时里每个不同新闻摘要的点击量,然后等再过了一小时后,依次遍历散列表中统计好的新闻摘要,判断当前遍历到的新闻摘要的点击量是否大于我们第一次构造出来的小顶堆的堆顶元素的点击量,如果大于则替换掉堆顶元素,然后进行堆化;否则跳过当前元素,遍历下一个新闻摘要元素的点击量……,直到将散列表中的新闻摘要元素遍历完。