HashMap 默认的初始大小是 16,最大装载因子默认是 0.75,底层采用链表法来解决冲突。在 JDK1.8 版本中,为了对 HashMap 做进一步优化,引入了红黑树。而当链表长度太长(默认超过 8)时,链表就转换为红黑树。
基础知识准备
^(异或运算符)
^是针对二进制的二目运算符。运算规则:两个二进制数值如果在同一位上相同,则结果中该位为0,否则为1,比如1011 & 0010 = 1001。|(或运算符)
|是针对二进制的二目运算符。运算规则:两个二进制数值如果在同一位上至少有一个1,则结果中该位为1,否则为0,比如1011 & 0010 = 1011。&(与运算符)
&是是针对二进制的二目运算符。需要注意的是&&是java中判断条件之间表示“和”的标识符,&是一个二目运算符,两个二进制数值如果在同一位上都是1,则结果中该位为1,否则为0,可以认为两个都是true(1),结果也为true(1),比如1011 & 0110 = 0010。
HashMap 默认的初始大小是 16,当然这个默认值是可以设置的,如果事先知道大概的数据量有多大,可以通过修改默认初始大小,减少动态扩容的次数,这样会大大提高 HashMap 的性能。
最大装载因子默认是 0.75,当 HashMap 中元素个数超过 0.75*capacity(capacity 表示散列表的容量)的时候,就会启动扩容,每次扩容都会扩容为原来的两倍大小。
HashMap 底层采用链表法来解决冲突。
于是,在 JDK1.8 版本中,为了对 HashMap 做进一步优化,我们引入了红黑树。而当链表长度太长(默认超过 8)时,链表就转换为红黑树。我们可以利用红黑树快速增删改查的特点,提高 HashMap 的性能。当红黑树结点个数少于 8 个的时候,又会将红黑树转化为链表。因为在数据量较小的情况下,红黑树要维护平衡,比起链表来,性能上的优势并不明显。
1 | int hash(Object key) { |
hash方法内的逻辑可以称为扰动函数
hashcode返回的是int最高32位,如果直接作为下标,大概40亿映射空间,如果散列函数设计的比较均匀,一般很难出现碰撞,但是一个40亿长度的数组,内存放不下
32位int型数据,右移16位,相当于用自己的高半位和低半位进行异或,以此来加大低位的随机性
这样设计,可以使高位的变化反应到低位,而且保证了随机性
A%B = A&(B-1),当B(散列表长度)为2的整次幂,相当于取模(位与运算的效率比求余高得多,从而提升了性能),可以保证index的位置分布均匀,以默认长度16为例,16-1=15,即00001111,“与”操作结果相当于截取最低四位,四位有0-15的16种可能性,相当于取模了,一切为了分布均匀!
HashMap如何控制数组的长度为2的整数次幂?
初始化指定长度
HashMap的数组长度为2的整数次幂,有利于上述[4]中的位与运算
如果指定一个非2的整数次幂,会自动转化成大于该指定数的最小2的整数次幂。如指定6则转化为8,指定11则转化为16。结合源码来分析,当我们初始化指定一个非2的整数次幂长度时,HashMap会调用tableSizeFor()方法
1 | static final int tableSizeFor(int cap) { |
1 | 举例:cap = 7-1 = 0000 0110 |
为什么必须要对cap进行-1之后再进行运算呢?如果指定的数刚好是2的整数次幂,如果没有-1结果会变成比他大两倍的数,如下:
1 | 举例:cap = 8 = 0000 1000 |
扩容时的长度增量
HashMap每次扩容的大小都是原来的两倍,控制了数组大小一定是2的整数次幂
1 | newThr = oldThr << 1; |
小结:
1.HashMap通过高16位和低16位异或运算来让高16位参与散列,且增加了低16位的随机性,提高了散列的效果
2.控制数组初始化的长度为2的整数次幂来简化取模运算,提高性能
3.扩容时也是翻倍处理,保证长度一直是2的整数次幂
哈希冲突解决方案
再优秀的hash算法永远无法避免出现hash冲突。hash冲突指的是两个不同的key经过hash计算之后得到的数组下标是相同的。解决hash冲突的方式很多,如开放定址法、再哈希法、公共溢出表法、链地址法。HashMap采用的是链地址法,jdk1.8之后还增加了红黑树的优化
出现冲突后,会在当前结点形成链表,当链表过长之后,会转化为红黑树( 时间复杂度 = O(logN) ),来提高效率,但红黑树只有在数据量较大时才能发挥它的优势。关于红黑树的转化,HashMap做了以下限制。
- 当链表的长度>=8且数组长度>=64时,会把链表转化成红黑树。
- 当链表长度>=8,但数组长度<64时,会优先进行扩容,而不是转化成红黑树。
- 当红黑树节点数<=6,自动转化成链表。
问题1:为什么需要数组大于64?
数组长度较短时,过早地使用红黑树,当发生扩容时,红黑树会被拆分,反而降低性能,所以一般长度低于64时,优先扩容
问题2:为什么大于等于8才转换红黑树?
树结点比普通结点大,在数据较少的情况下,体现不出优势,而且浪费空间,在理论数学计算中,链表长度达到8的概率是百万分之一。
扩容方案
扩容之后需要进行数据迁移:
JDK1.7之前的数据迁移比较简单,就是遍历所有的节点,把所有的节点依次通过hash函数计算新的下标,再插入到新数组的链表中。
这样会有两个缺点:
1、每个节点都需要进行一次求余计算;
2、插入到新的数组时候采用的是头插入法,在多线程环境下会形成链表环。
jdk1.8之后进行了优化,原因在于他控制数组的长度始终是2的整数次幂,每次扩展数组都是原来的2倍,带来的好处是key在新的数组的hash结果只有两种:在原来的位置,或者在原来位置+原数组长度。
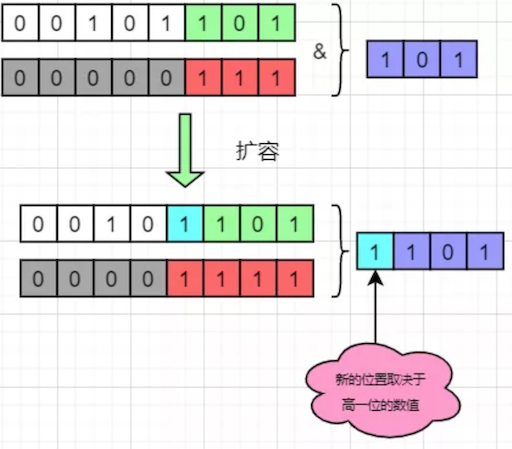
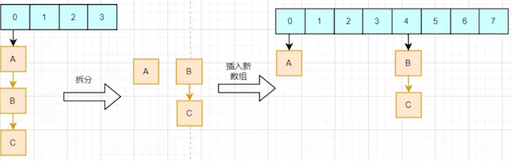
从图中我们可以看到,在新数组中的hash结果,仅仅取决于高一位的数值。如果高一位是0,那么计算结果就是在原位置,而如果是1,则加上原数组的长度即可。这样我们只需要判断一个节点的高一位是1 or 0就可以得到他在新数组的位置,而不需要重复hash计算。HashMap把每个链表拆分成两个链表,对应原位置或原位置+原数组长度,再分别插入到新的数组中,保留原来的节点顺序,如下:
小结:
- 装载因子决定了HashMap扩容的阈值,需要权衡时间与空间,一般情况下保持0.75不作改动;
- HashMap扩容机制结合了数组长度为2的整数次幂的特点,以一种更高的效率完成数据迁移,同时避免头插法造成链表环。
线程安全
HashMap并不是线程安全的,在多线程的情况下无法保证数据的一致性。举个例子:HashMap下标2的位置为null,线程A需要将节点X插入下标2的位置,在判断是否为null之后,线程被挂起;此时线程B把新的节点Y插入到下标2的位置;恢复线程A,节点X会直接插入到下标2,覆盖节点Y,导致数据丢失
jdk1.7及以前扩容时采用的是头插法,这种方式插入速度快,但在多线程环境下会造成链表环,而链表环会在下一次插入时找不到链表尾而发生死循环。jdk1.8之后扩容采用了尾插法,解决了这个问题,但并没有解决数据的一致性问题。
解决这个问题有三个方案:
- 采用Hashtable
- 调用Collections.synchronizeMap()方法来让HashMap具有多线程能力
- 采用ConcurrentHashMap
前两个方案的思路是相似的,均是每个方法中,对整个对象进行上锁。
Hashtable是老一代的集合框架,很多的设计均以及落后,他在每一个方法中均加上了synchronize关键字保证线程安全。
1 | // Hashtable |
这种简单粗暴锁整个对象的方式造成的后果是:
锁是非常重量级的,会严重影响性能。
同一时间只能有一个线程进行读写,限制了并发效率。
ConcurrentHashMap的设计就是为了解决此问题。他通过降低锁粒度+CAS的方式来提高效率。简单来说,ConcurrentHashMap锁的并不是整个对象,而是一个数组的一个节点,那么其他线程访问数组其他节点是不会互相影响,极大提高了并发效率;同时ConcurrentHashMap读操作并不需要获取锁
1 | ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>(); |
当Thread1调用containsKey之后释放锁,Thread2获得锁并把“abc”移除再释放锁,这个时候Thread1读取到的s就是一个null了,也就出现了问题了。所以ConcurrentHashMap类或者Collections.synchronizeMap()方法或者Hashtable都只能在一定的限度上保证线程安全,而无法保证绝对线程安全。
关于线程安全,还有一个fast-fail问题,即快速失败。当使用HashMap的迭代器遍历HashMap时,如果此时HashMap发生了结构性改变,如插入新数据、移除数据、扩容等,那么Iteractor会抛出fast-fail异常,防止出现并发异常,在一定限度上保证了线程安全
小结
HashMap并不能保证线程安全,在多线程并发访问下会出现意想不到的问题,如数据丢失等HashMap1.8采用尾插法进行扩容,防止出现链表环导致的死循环问题解决并发问题的的方案有Hashtable、Collections.synchronizeMap()、ConcurrentHashMap。其中最佳解决方案是ConcurrentHashMap上述解决方案并不能完全保证线程安全快速失败是HashMap迭代机制中的一种并发安全保证