数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
第一是线性表(Linear List)。顾名思义,线性表就是数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向。其实除了数组,链表、队列、栈等也是线性表结构。
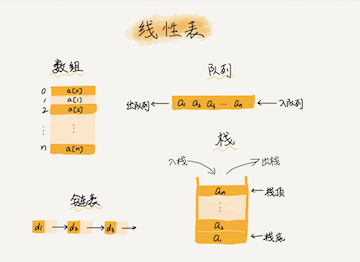
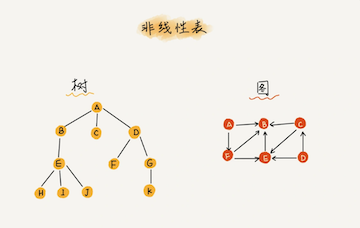
而与它相对立的概念是非线性表,比如二叉树、堆、图等。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。
第二个是连续的内存空间和相同类型的数据。正是因为这两个限制,它才有了一个堪称“杀手锏”的特性:“随机访问”。但有利就有弊,这两个限制也让数组的很多操作变得非常低效,比如要想在数组中删除、插入一个数据,为了保证连续性,就需要做大量的数据搬移工作。
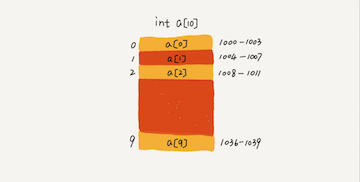
计算机会给每个内存单元分配一个地址,计算机通过地址来访问内存中的数据。当计算机需要随机访问数组中的某个元素时,它会首先通过下面的寻址公式,计算出该元素存储的内存地址:
1 | a[i]_address = base_address + i * data_type_size |
数组支持随机访问,根据下标随机访问的时间复杂度为 O(1)。(访问不等于查找,不同概念)
插入操作
在每个位置插入元素的概率是一样的,所以平均情况时间复杂度为 (1+2+…n)/n=O(n)。
删除操作
平均情况时间复杂度也为 O(n)
- 1.Java ArrayList 无法存储基本类型,比如 int、long,需要封装为 Integer、Long 类,而 Autoboxing、Unboxing 则有一定的性能消耗,所以如果特别关注性能,或者希望使用基本类型,就可以选用数组。
- 如果数据大小事先已知,并且对数据的操作非常简单,用不到 ArrayList 提供的大部分方法,也可以直接使用数组。
- 3.当要表示多维数组时,用数组往往会更加直观。
为什么大多数编程语言中,数组要从 0 开始编号,而不是从 1 开始呢?
从数组存储的内存模型上来看,“下标”最确切的定义应该是“偏移(offset)”。前面也讲到,如果用 a 来表示数组的首地址,a[0]就是偏移为 0 的位置,也就是首地址,a[k]就表示偏移 k 个 type_size 的位置,所以计算 a[k]的内存地址只需要用这个公式:
1 | a[k]_address = base_address + k * type_size |
但是,如果数组从 1 开始计数,那我们计算数组元素 a[k]的内存地址就会变为:
1 | a[k]_address = base_address + (k-1)*type_size |
对比两个公式,我们不难发现,从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对于 CPU 来说,就是多了一次减法指令。
链表Linked List
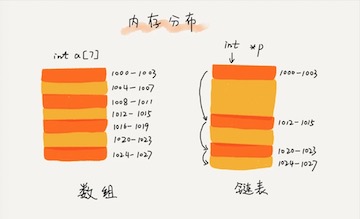
数组需要一块连续的内存空间来存储,对内存的要求比较高。如果我们申请一个 100MB 大小的数组,当内存中没有连续的、足够大的存储空间时,即便内存的剩余总可用空间大于 100MB,仍然会申请失败。而链表恰恰相反,它并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用,所以如果我们申请的是 100MB 大小的链表,根本不会有问题。
单链表
链表通过指针将一组零散的内存块串联在一起。其中,我们把内存块称为链表的“结点”。为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址。
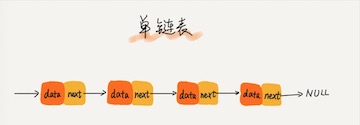
双向链表
单向链表只有一个方向,结点只有一个后继指针 next 指向后面的结点。而双向链表,顾名思义,它支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。
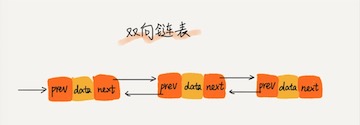
双向循环链表
优缺点:
数组简单易用,在实现上使用的是连续的内存空间,可以借助 CPU 的缓存机制,预读数组中的数据,所以访问效率更高。而链表在内存中并不是连续存储,所以对 CPU 缓存不友好,没办法有效预读。
数组的缺点是大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配给它,导致“内存不足(out of memory)”。如果声明的数组过小,则可能出现不够用的情况。这时只能再申请一个更大的内存空间,把原数组拷贝进去,非常费时。链表本身没有大小的限制,天然地支持动态扩容,我觉得这也是它与数组最大的区别。
基于链表实现 LRU 缓存淘汰算法
如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部。
如果此数据没有在缓存链表中,又可以分为两种情况:
1)如果此时缓存未满,则将此结点直接插入到链表的头部;
2)如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部。
理解指针或引用的含义
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
p->next=q。这行代码是说,p 结点中的 next 指针存储了 q 结点的内存地址。
p->next=p->next->next。这行代码表示,p 结点的 next 指针存储了 p 结点的下下一个结点的内存地址。
警惕指针丢失和内存泄漏
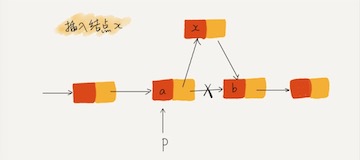
在结点 a 和相邻的结点 b 之间插入结点 x,假设当前指针 p 指向结点 a
1 | x->next = p->next; // 将x的结点的next指针指向b结点; |
插入结点时,一定要注意操作的顺序,要先将结点 x 的 next 指针指向结点 b,再把结点 a 的 next 指针指向结点 x,这样才不会丢失指针,导致内存泄漏
利用哨兵简化实现难度
首先,我们先来回顾一下单链表的插入和删除操作。如果我们在结点 p 后面插入一个新的结点,只需要下面两行代码就可以搞定。
1 | new_node->next = p->next; |
当我们要向一个空链表中插入第一个结点
1 | if (head == null) { |
如果要删除结点 p 的后继结点,我们只需要一行代码就可以搞定。
1 | p->next = p->next->next; |
如果我们要删除链表中的最后一个结点
1 | if (head->next == null) { |
如果我们引入哨兵结点,在任何时候,不管链表是不是空,head 指针都会一直指向这个哨兵结点。我们也把这种有哨兵结点的链表叫带头链表。相反,没有哨兵结点的链表就叫作不带头链表。我画了一个带头链表,你可以发现,哨兵结点是不存储数据的。因为哨兵结点一直存在,所以插入第一个结点和插入其他结点,删除最后一个结点和删除其他结点,都可以统一为相同的代码实现逻辑了。
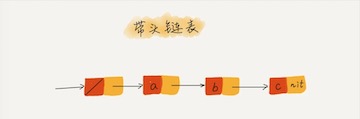
重点留意边界条件处理
1.如果链表为空时,代码是否能正常工作?
2.如果链表只包含一个结点时,代码是否能正常工作?
3.如果链表只包含两个结点时,代码是否能正常工作?
4.代码逻辑在处理头结点和尾结点的时候,是否能正常工作?
举例画图,辅助思考
。。。
多写多练,没有捷径
1.单链表反转
2.链表中环的检测
3.两个有序的链表合并
4.删除链表倒数第 n 个结点
5.求链表的中间结点
1 | // 单链表反转 |
1 | // 检测环 |
1 | // 有序链表合并 Leetcode 21 |
1 | // 删除倒数第K个结点 |
1 | // 求中间结点 |
参考文章:
https://time.geekbang.org/column/article/40961
https://time.geekbang.org/column/article/41149