当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出、先进后出的特性,这时我们就应该首选“栈”这种数据结构。栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作顺序栈,用链表实现的栈,我们叫作链式栈。
栈Stack
1 | // 基于数组实现的顺序栈 |
置不置空没关系,因为栈操作是跟着count走的,它在进栈的时候会覆盖那个原先的栈顶。不管是顺序栈还是链式栈,入栈、出栈只涉及栈顶个别数据的操作,所以时间复杂度都是 O(1)。
如果要实现一个支持动态扩容的栈,我们只需要底层依赖一个支持动态扩容的数组就可以了。当栈满了之后,我们就申请一个更大的数组,将原来的数据搬移到新数组中。
对于出栈操作来说,我们不会涉及内存的重新申请和数据的搬移,所以出栈的时间复杂度仍然是 O(1)。但是,对于入栈操作来说,情况就不一样了。当栈中有空闲空间时,入栈操作的时间复杂度为 O(1)。但当空间不够时,就需要重新申请内存和数据搬移,所以时间复杂度就变成了 O(n)。
均摊时间复杂度一般都等于最好情况时间复杂度。因为在大部分情况下,入栈操作的时间复杂度 O 都是 O(1),只有在个别时刻才会退化为 O(n),所以把耗时多的入栈操作的时间均摊到其他入栈操作上,平均情况下的耗时就接近 O(1)。
栈在函数调用中的应用
比较经典的一个应用场景就是函数调用栈。
操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。
1 | int main() { |
栈在表达式求值中的应用
实际上,编译器就是通过两个栈来实现的。其中一个保存操作数的栈,另一个是保存运算符的栈。我们从左向右遍历表达式,当遇到数字,我们就直接压入操作数栈;当遇到运算符,就与运算符栈的栈顶元素进行比较。
如果比运算符栈顶元素的优先级高,就将当前运算符压入栈;如果比运算符栈顶元素的优先级低或者相同,从运算符栈中取栈顶运算符,从操作数栈的栈顶取 2 个操作数,然后进行计算,再把计算完的结果压入操作数栈,继续比较。
栈在括号匹配中的应用
比如,{[] ()[{}]}或[{()}([])]等都为合法格式,而{[}()]或[({)]为不合法的格式。
我们用栈来保存未匹配的左括号,从左到右依次扫描字符串。当扫描到左括号时,则将其压入栈中;当扫描到右括号时,从栈顶取出一个左括号。如果能够匹配,比如“(”跟“)”匹配,“[”跟“]”匹配,“{”跟“}”匹配,则继续扫描剩下的字符串。如果扫描的过程中,遇到不能配对的右括号,或者栈中没有数据,则说明为非法格式。
如何实现浏览器的前进、后退功能?
其实,用两个栈就可以非常完美地解决这个问题。我们使用两个栈,X 和 Y,我们把首次浏览的页面依次压入栈 X,当点击后退按钮时,再依次从栈 X 中出栈,并将出栈的数据依次放入栈 Y。当我们点击前进按钮时,我们依次从栈 Y 中取出数据,放入栈 X 中。当栈 X 中没有数据时,那就说明没有页面可以继续后退浏览了。当栈 Y 中没有数据,那就说明没有页面可以点击前进按钮浏览了。
你通过页面 b 又跳转到新的页面 d 了,页面 c 就无法再通过前进、后退按钮重复查看了,所以需要清空栈 Y。
列队Queue
先进者先出,这就是典型的“队列”。
栈只支持两个基本操作:入栈 push()和出栈 pop()。队列跟栈非常相似,支持的操作也很有限,最基本的操作也是两个:入队 enqueue(),放一个数据到队列尾部;出队 dequeue(),从队列头部取一个元素。队列跟栈一样,也是一种操作受限的线性表数据结构。
用数组实现的栈叫作顺序栈,用链表实现的栈叫作链式栈。同样,用数组实现的队列叫作顺序队列,用链表实现的队列叫作链式队列。
对于栈来说,我们只需要一个栈顶指针就可以了。但是队列需要两个指针:一个是 head 指针,指向队头;一个是 tail 指针,指向队尾。
基于数组的实现方法
当 a、b、c、d 依次入队之后,队列中的 head 指针指向下标为 0 的位置,tail 指针指向下标为 4 的位置。当我们调用两次出队操作之后,队列中 head 指针指向下标为 2 的位置,tail 指针仍然指向下标为 4 的位置。当队列的 tail 指针移动到数组的最右边后,如果有新的数据入队,我们可以将 head 到 tail 之间的数据,整体搬移到数组中 0 到 tail-head 的位置。
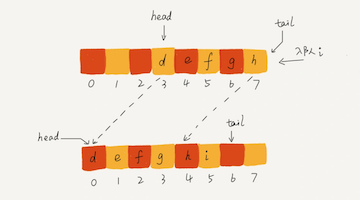
出队操作的时间复杂度是 O(1)
入队操作的时间复杂度是:最差时间复杂度是O(n),最好是O(1),均摊后就是O(1)。)
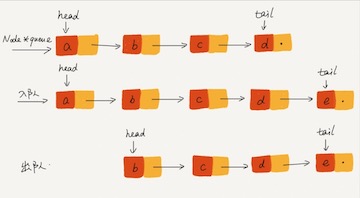
基于链表的队列实现方法
入队时,tail->next= new_node, tail = tail->next;出队时,head = head->next。
循环队列
在用数组实现的非循环队列中,队满的判断条件是 tail == n,队空的判断条件是 head == tail。
(如果所有空间都填满的话队空跟队满都是tail==head了,就无法判断当前状态是队空还是队满。为了达到判断队列状态的目的,可以通过牺牲一个存储空间来实现。)
针对循环队列,队列为空的判断条件仍然是 head == tail。当队满时,(tail+1)%n=head。
(有个特殊情况,当tail = n-1,而head = 0时,这时候,tail+1 = n,而head = 0,所以使用 (tail+1) %n的值)
阻塞队列和并发队列
简单来说,就是在队列为空的时候,从队头取数据会被阻塞。因为此时还没有数据可取,直到队列中有了数据才能返回;如果队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回。
消费者线程取数据,生产者线程插入数据,基于阻塞队列,我们还可以通过协调“生产者”和“消费者”的个数,来提高数据的处理效率。我们可以多配置几个“消费者”,来应对一个“生产者”。这个时候就会存在线程安全问题。
线程安全的队列我们叫作并发队列。最简单直接的实现方式是直接在 enqueue()、dequeue() 方法上加锁,但是锁粒度大并发度会比较低,同一时刻仅允许一个存或者取操作。
线程池没有空闲线程时,新的任务请求线程资源时,线程池该如何处理?
基于链表的实现方式,可以实现一个支持无限排队的无界队列(unbounded queue),但是可能会导致过多的请求排队等待,请求处理的响应时间过长。所以,针对响应时间比较敏感的系统,基于链表实现的无限排队的线程池是不合适的。
而基于数组实现的有界队列(bounded queue),队列的大小有限,所以线程池中排队的请求超过队列大小时,接下来的请求就会被拒绝,这种方式对响应时间敏感的系统来说,就相对更加合理。不过,设置一个合理的队列大小,也是非常有讲究的。队列太大导致等待的请求太多,队列太小会导致无法充分利用系统资源、发挥最大性能。
实际上,对于大部分资源有限的场景,当没有空闲资源时,基本上都可以通过“队列”这种数据结构来实现请求排队。
参考文章:
https://time.geekbang.org/column/article/41222
https://time.geekbang.org/column/article/41440