冒泡排序、插入排序、选择排序 O(n^2),归并排序、快速排序 O(nlogn),计数排序、基数排序、桶排序 O(n)
冒泡排序(Bubble Sort)
冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。一次冒泡会让至少一个元素移动到它应该在的位置,重复 n 次,就完成了 n 个数据的排序工作。
1 | // 冒泡排序,a表示数组,n表示数组大小 |
有序度是数组中具有有序关系的元素对的个数
有序元素对:a[i] <= a[j],i < j
逆序元素对:a[i] > a[j],i < j
逆序度 = 满有序度 - 有序度
冒泡排序包含两个操作原子,比较和交换。每交换一次,有序度就加 1。不管算法怎么改进,交换次数总是确定的,即为逆序度,也就是n*(n-1)/2–初始有序度。
对于包含 n 个数据的数组进行冒泡排序,平均交换次数是多少呢?最坏情况下,初始状态的有序度是 0,所以要进行 n*(n-1)/2 次交换。最好情况下,初始状态的有序度是 n*(n-1)/2,就不需要进行交换。我们可以取个中间值 n*(n-1)/4,来表示初始有序度既不是很高也不是很低的平均情况。
换句话说,平均情况下,需要 n*(n-1)/4 次交换操作,比较操作肯定要比交换操作多,而复杂度的上限是 O(n2),所以平均情况下的时间复杂度就是 O(n2)。
是原地算法,是稳定算法平均情况下的时间复杂度就是 O(n2)。最好情况时间复杂度是 O(n)。而最坏的情况是,要排序的数据刚好是倒序排列的,我们需要进行 n 次冒泡操作,所以最坏情况时间复杂度为 O(n2)
插入排序(Insertion Sort)
插入排序的移动次数 == 冒泡排序的交换次数 == 逆序度
插入算法的核心思想是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。重复这个过程,直到未排序区间中元素为空,算法结束。(初始时,已排序区间为数据中第一个元素)
插入排序也包含两种操作,一种是元素的比较,一种是元素的移动。当我们需要将一个数据 a 插入到已排序区间时,需要拿 a 与已排序区间的元素依次比较大小,找到合适的插入位置。找到插入点之后,我们还需要将插入点之后的元素顺序往后移动一位,这样才能腾出位置给元素 a 插入。
对于不同的查找插入点方法(从头到尾、从尾到头),元素的比较次数是有区别的。但对于一个给定的初始序列,移动操作的次数总是固定的,就等于逆序度。
1 | public static void insert_sort(int[] a, int n) { |
是原地算法,是稳定算法最坏情况时间复杂度为 O(n2)最好是时间复杂度为 O(n)平均时间复杂度为 O(n2)
选择排序(Selection Sort)
选择排序算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。
但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。
是原地算法,是一种不稳定的排序算法最好情况时间复杂度为 O(n2)最坏情况时间复杂度为 O(n2)平均情况时间复杂度为 O(n2)
比如 5,8,5,2,9 这样一组数据,使用选择排序算法来排序的话,第一次找到最小元素 2,与第一个 5 交换位置,那第一个 5 和中间的 5 顺序就变了,所以就不稳定了。正是因此,相对于冒泡排序和插入排序,选择排序就稍微逊色了。
冒泡排序不管怎么优化,元素交换的次数是一个固定值,是原始数据的逆序度。插入排序是同样的,不管怎么优化,元素移动的次数也等于原始数据的逆序度。从代码实现上来看,冒泡排序的数据交换要比插入排序的数据移动要复杂,冒泡排序需要 3 个赋值操作,而插入排序只需要 1 个。
归并排序(Merge Sort)
先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
递推公式:merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
终止条件:p >= r 不用再继续分解
合并
申请一个临时数组 tmp,大小与 A[p…r]相同。我们用两个游标 i 和 j,分别指向 A[p…q]和 A[q+1…r]的第一个元素。比较这两个元素 A[i]和 A[j],如果 A[i]<=A[j],我们就把 A[i]放入到临时数组 tmp,并且 i 后移一位,否则将 A[j]放入到数组 tmp,j 后移一位。
继续上述比较过程,直到其中一个子数组中的所有数据都放入临时数组中,再把另一个数组中的数据依次加入到临时数组的末尾,这个时候,临时数组中存储的就是两个子数组合并之后的结果了。最后再把临时数组 tmp 中的数据拷贝到原数组 A[p…r]中。
merge() 合并函数如果借助哨兵,代码就会简洁很多,数组末尾添加一个Int.MAXValue,就能省去上述紫色文字中的逻辑,很巧妙!!!!!!!
非原地算法,是稳定算法归并排序的执行效率与要排序的原始数组的有序程度无关,所以其时间复杂度是非常稳定的最好情况、最坏情况,还是平均情况,时间复杂度都是 O(nlogn)。空间复杂度是 O(n)。
快速排序算法(Quicksort)
如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。根据分治、递归的处理思想,我们可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
递推公式:quick_sort(p…r) = quick_sort(p…q-1) + quick_sort(q+1… r)
终止条件:p >= r
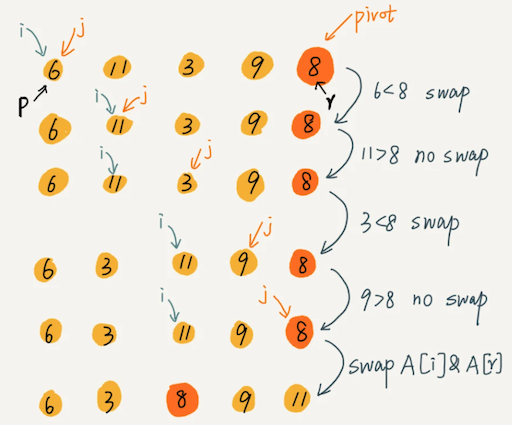
i像钉子,盯住比pivot大的值;j扫描,遇到比pivot小的值就和i交换。扫描结束时,i左右的值都比pivot小,i及i右边的值大于等于pivot。此时交换A[i]和pivot(原地算法的实现)
不是一个稳定的排序算法是原地算法分区极其均衡O(nlogn)分区极其不均衡 O(n2)平均情况时间复杂度O(nlogn)
桶排序、计数排序、基数排序
因为这些排序算法的时间复杂度是线性的,所以我们把这类排序算法叫作线性排序(Linear sort)。之所以能做到线性的时间复杂度,主要原因是,这三个算法是非基于比较的排序算法,都不涉及元素之间的比较操作。
桶排序(Bucket sort)
如果要排序的数据有 n 个,我们把它们均匀地划分到 m 个桶内,每个桶里就有 k=n/m 个元素。每个桶内部使用快速排序,时间复杂度为 O(k * logk)。m 个桶排序的时间复杂度就是 O(m * k * logk),因为 k=n/m,所以整个桶排序的时间复杂度就是 O(n*log(n/m))。当桶的个数 m 接近数据个数 n 时,log(n/m) 就是一个非常小的常量,这个时候桶排序的时间复杂度接近 O(n)。
桶排序对要排序数据的要求是非常苛刻的。
首先,要排序的数据需要很容易就能划分成 m 个桶,并且,桶与桶之间有着天然的大小顺序。这样每个桶内的数据都排序完之后,桶与桶之间的数据不需要再进行排序。
其次,数据在各个桶之间的分布是比较均匀的。如果数据经过桶的划分之后,有些桶里的数据非常多,有些非常少,很不平均,那桶内数据排序的时间复杂度就不是常量级了。在极端情况下,如果数据都被划分到一个桶里,那就退化为 O(nlogn) 的排序算法了。
桶排序比较适合用在外部排序中。所谓的外部排序就是数据存储在外部磁盘中,数据量比较大,内存有限,无法将数据全部加载到内存中。
如果数据均匀,分成几部分,每部分加载到内存进行快速排序
如果数据分布不均匀,有些桶的数据很大,则这个桶继续拆分,直到所有的文件都能读入内存为止
计数排序(Counting sort)
当要排序的 n 个数据,所处的范围并不大的时候,比如最大值是 k,我们就可以把数据划分成 k 个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间。
计数排序只能用在数据范围不大的场景中,如果数据范围 k 比要排序的数据 n 大很多,就不适合用计数排序了。而且,计数排序只能给非负整数排序,如果要排序的数据是其他类型的,要将其在不改变相对大小的情况下,转化为非负整数。
比如,还是拿考生这个例子。如果考生成绩精确到小数后一位,我们就需要将所有的分数都先乘以 10,转化成整数,然后再放到 9010 个桶内。再比如,如果要排序的数据中有负数,数据的范围是[-1000, 1000],那我们就需要先对每个数据都加 1000,转化成非负整数。
基数排序(Radix sort)
基数排序之所以不是原地排序,是因为根据每一位来排序的时候的,会选择桶排序或者计数排序。
比如 比较11位手机号码:
先按照最后一位来排序手机号码,然后,再按照倒数第二位重新排序,以此类推,最后按照第一位重新排序。经过 11 次排序之后,手机号码就都有序了。
从后往前排比从前往后排要好
从前往后排:排好了第一位数,排第二位数的时候,还需要保证第一位数是有序的。就相当于排第一位数时,需要分桶,1 在第一个桶,2 在第二个桶,然后在每个桶里面再进行第二位数的排序。 比如有三个数: 132 213 123 根据第一位排序的结果: 132 123 213 根据第二位排序的结果(假设不考虑第一位): 213 123 132 那这样就错了,需要基于第一位的排序结果再进行排序才行: 123 132 213 从后往前排:排好了最后一位数,排倒数第二位数时,不需要再考虑最后一位数了。反正是左边的数优先级更高。
实际上,有时候要排序的数据并不都是等长的,比如我们排序牛津字典中的 20 万个英文单词,最短的只有 1 个字母,最长的我特意去查了下,有 45 个字母,中文翻译是尘肺病。对于这种不等长的数据,基数排序还适用吗?实际上,我们可以把所有的单词补齐到相同长度,位数不够的可以在后面补“0”,因为根据ASCII 值,所有字母都大于“0”,所以补“0”不会影响到原有的大小顺序。这样就可以继续用基数排序了。
如何选择合适的排序算法?
线性排序算法的时间复杂度比较低,适用场景比较特殊。所以如果要写一个通用的排序函数,不能选择线性排序算法。
如果对小规模数据进行排序,可以选择时间复杂度是 O(n2) 的算法;如果对大规模数据进行排序,时间复杂度是 O(nlogn) 的算法更加高效。所以,为了兼顾任意规模数据的排序,一般都会首选时间复杂度是 O(nlogn) 的排序算法来实现排序函数。
归并排序并不是原地排序算法,空间复杂度是 O(n)。所以,粗略点、夸张点讲,如果要排序 100MB 的数据,除了数据本身占用的内存之外,排序算法还要额外再占用 100MB 的内存空间,空间耗费就翻倍了。
快速排序比较适合来实现排序函数,但是,我们也知道,快速排序在最坏情况下的时间复杂度是 O(n2),如何来解决这个“复杂度恶化”的问题呢?
如果数据原来就是有序的或者接近有序的,每次分区点都选择最后一个数据,那快速排序算法就会变得非常糟糕,时间复杂度就会退化为 O(n2)。实际上,这种 O(n2) 时间复杂度出现的主要原因还是因为我们分区点选得不够合理。
最理想的分区点是:被分区点分开的两个分区中,数据的数量差不多。
- 三数取中法
我们从区间的首、尾、中间,分别取出一个数,然后对比大小,取这 3 个数的中间值作为分区点。这样每间隔某个固定的长度,取数据出来比较,将中间值作为分区点的分区算法,肯定要比单纯取某一个数据更好。但是,如果要排序的数组比较大,那“三数取中”可能就不够了,可能要“五数取中”或者“十数取中”。
- 随机法
随机法就是每次从要排序的区间中,随机选择一个元素作为分区点。这种方法并不能保证每次分区点都选的比较好,但是从概率的角度来看,也不大可能会出现每次分区点都选得很差的情况,所以平均情况下,这样选的分区点是比较好的。时间复杂度退化为最糟糕的 O(n2) 的情况,出现的可能性不大。
举例分析排序函数
Glibc 中的 qsort() 函数举例
要排序的数据量比较小的时候,qsort() 会优先使用归并排序来排序输入数据
要排序的数据量比较大的时候,qsort() 会改为用快速排序算法来排序。qsort() 选择分区点的方法就是“三数取中法”。还有我们前面提到的递归太深会导致堆栈溢出的问题,qsort() 是通过自己实现一个堆上的栈,手动模拟递归来解决的。当要排序的区间中,元素的个数小于等于 4 时,qsort() 就退化为插入排序,不再继续用递归来做快速排序,因为我们前面也讲过,在小规模数据面前,O(n2) 时间复杂度的算法并不一定比 O(nlogn) 的算法执行时间长
在大 O 复杂度表示法中,我们会省略低阶、系数和常数,也就是说,O(nlogn) 在没有省略低阶、系数、常数之前可能是 O(knlogn + c),而且 k 和 c 有可能还是一个比较大的数。
假设 k=1000,c=200,当我们对小规模数据(比如 n=100)排序时,n2的值实际上比 knlogn+c 还要小。
knlogn+c = 1000 * 100 * log100 + 200 远大于10000
n^2 = 100*100 = 10000
所以,对于小规模数据的排序,O(n2) 的排序算法并不一定比 O(nlogn) 排序算法执行的时间长。对于小数据量的排序,我们选择比较简单、不需要递归的插入排序算法。
glibc的qsort()实现: 小规模数据(1~2k):归并 大规模数据(如100M):快排 快排过程中如果区间元素个数<=4:插入排序 小规模数据下,O(n^2)不一定比O(nlogn)运行慢
参考文章:
https://time.geekbang.org/column/article/41802
https://time.geekbang.org/column/article/41913
https://time.geekbang.org/column/article/42038
https://time.geekbang.org/column/article/42359